

Not all data masking tools are built for the same kind of job. Some are better suited for locked-in enterprise stacks; others focus on flexibility across fragmented systems. In this article, you’ll find K2View vs Oracle Data Masking comparison through the lens of performance, ease of use, integration range, scalability, and compliance coverage. If you’re deciding how to anonymize sensitive data without slowing down your workflow — or boxing yourself into one ecosystem — this breakdown offers a clear look at what each tool does well, where it falls short, and where a third option may outpace them both.

What is K2View?
K2View is a data operations platform designed to manage, secure, and deliver data at scale — often used in test data management, data integration, and data masking. Its masking solution focuses on speed, flexibility, and consistent protection across multiple data sources, including structured and unstructured data.
Key Features
K2View’s masking engine is built around the concept of “micro-databases,” which store all data related to a specific business entity (like a customer or device). This makes it possible to apply consistent masking rules across fragmented systems. The platform supports on-the-fly and static masking, handles structured and unstructured data, preserves referential integrity, and offers synthetic data generation. It also includes automated PII discovery.
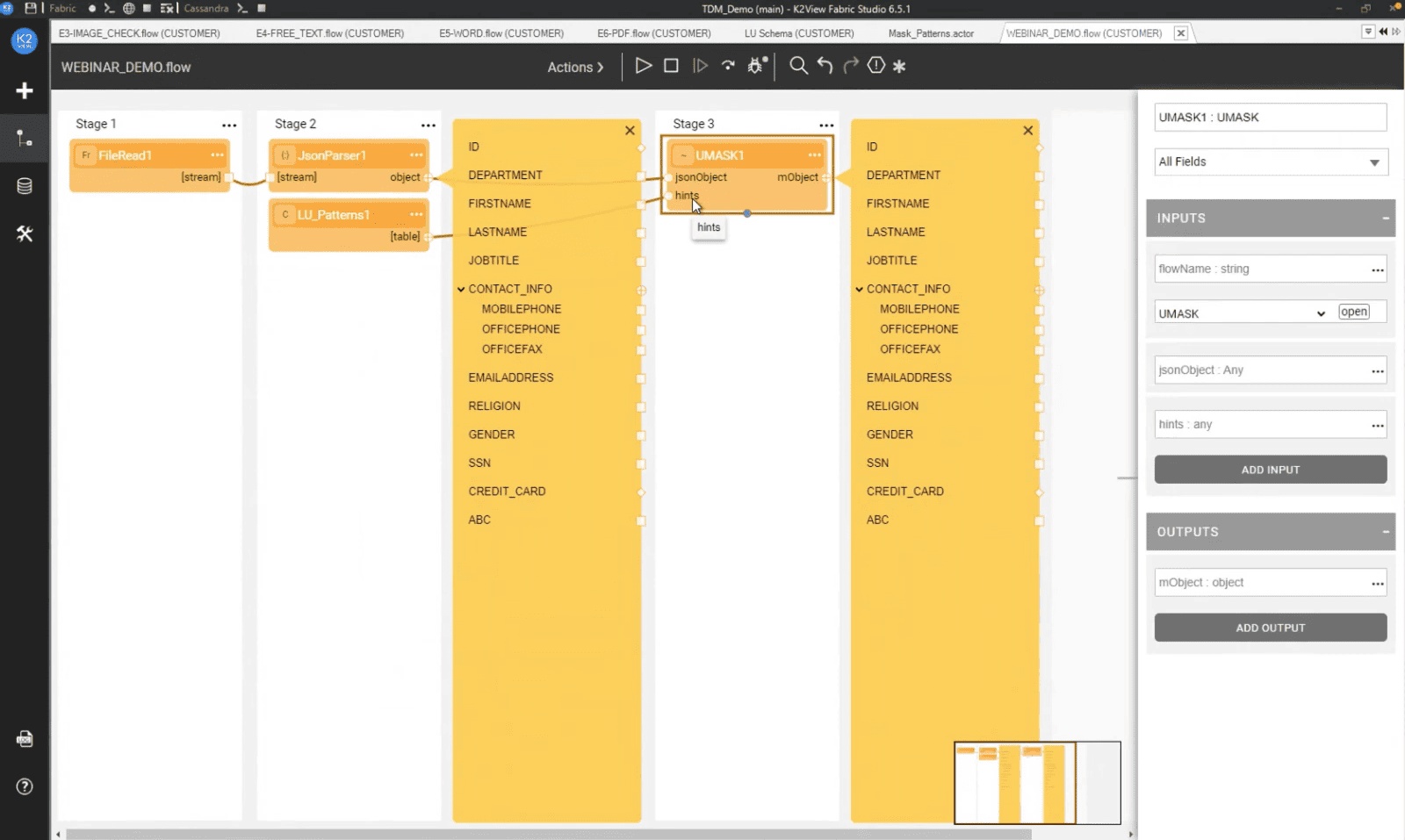
Advantages
- Works with any data source — relational, NoSQL, flat files, or APIs
- Fast processing at scale, with masking jobs split and parallelized
- Built-in support for unstructured data and synthetic data generation
- Centralized rule definitions tied to business entities
- Real-time masking options for live environments
- Strong compliance support (e.g., GDPR, HIPAA)
Disadvantages
- Requires upfront modeling of business entities, which adds complexity
- On-prem deployments may take time to set up and optimize
- Learning curve can be steep for teams without prior K2View experience
- Automation for recurring masking jobs may require custom workflows
- Premium pricing aimed at enterprise-scale use cases
Price
K2View offers both SaaS and on-premises licensing. Cloud pricing starts around $75,000 per year, with additional costs depending on usage volume (e.g. data processed, storage). On-prem pricing is customized and typically based on number of environments or data sources. A free trial is available.
If you are not sure whether K2View is for you – check out our K2View alternatives list.
What is Oracle Data Masking?
Oracle Data Masking and Subsetting is an add-on for Oracle Enterprise Manager, built to help teams anonymize sensitive data in non-production Oracle databases. It supports a range of masking techniques and includes tools for reducing database size through subsetting. The solution is primarily designed for organizations already operating within the Oracle ecosystem.
Key Features
Oracle’s masking tool offers format-preserving masking, conditional masking, deterministic replacements, and compound masking. It includes automated discovery of sensitive data, integration with Application Data Modeling (ADM), and a masking format library. The subsetting feature allows teams to create smaller, representative datasets, helping reduce storage and exposure. While optimized for Oracle databases, it can also connect to external data sources using Oracle gateways.
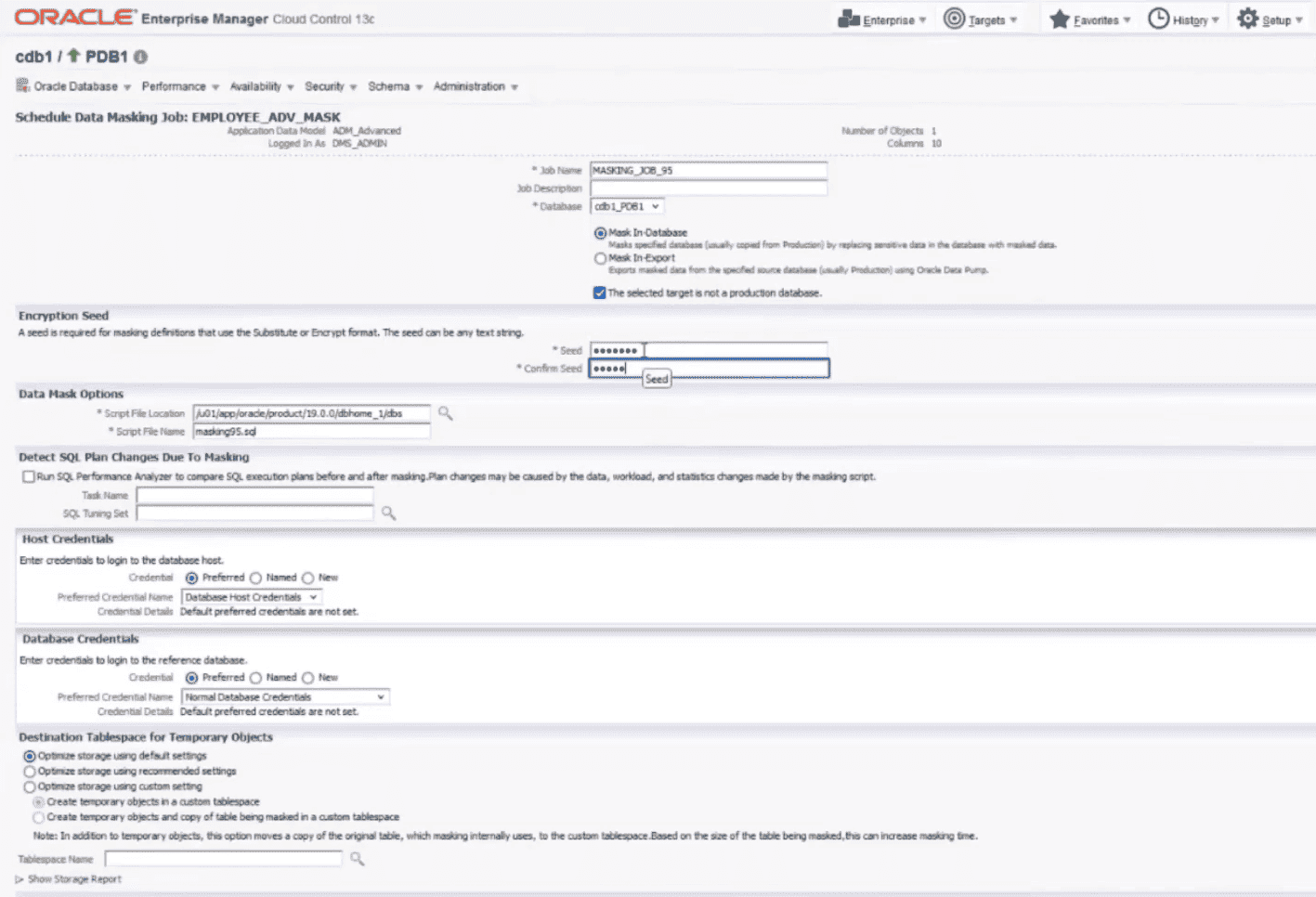
Advantages
- Deep integration with Oracle Database and Enterprise Manager
- Wide range of masking methods with built-in format templates
- Supports referential integrity and application-level consistency
- Includes data subsetting to reduce test database size
- Prebuilt templates for Oracle applications (e.g. E-Business Suite)
- Cloud and on-prem deployment options via Oracle Data Safe
Disadvantages
- Mainly limited to Oracle environments — external DB support is limited and complex
- No dynamic masking for live data (requires a separate feature)
- High learning curve, especially when managing complex data models
- Performance impact during masking jobs on large databases
- Requires Enterprise Edition and separate licensing for the masking pack
Price
Oracle Data Masking and Subsetting Pack is licensed separately from the core database. On-premises, it starts at approximately $11,500 per processor (plus support). Named User Plus pricing is also available. In Oracle Cloud, similar functionality is included in Data Safe at no extra cost for OCI-hosted databases. For masking databases outside Oracle Cloud, additional charges apply.
Differences Between Oracle Data Masking and K2View
While both tools are designed to anonymize sensitive data, they take fundamentally different approaches. Below you’ll find the main K2View vs Oracle differences — and how they affect implementation and long-term use.
Architecture
K2View is built around a micro-database architecture that organizes data by business entity. This design allows masking rules to be applied consistently across distributed systems and enables real-time or batch operations.
Oracle Data Masking, on the other hand, is tightly coupled with the Oracle Database engine. It performs masking tasks inside the database, which keeps data in place but limits flexibility. Subsetting and masking are performed on database copies, not in real time.
Integration Support
K2View is database-agnostic. It can ingest and mask data from a wide range of sources — relational, NoSQL, flat files, APIs, and even unstructured data. This makes it more suitable for organizations with complex, hybrid data landscapes.
Oracle’s solution is designed primarily for Oracle environments. While it can connect to external databases through Oracle gateways, doing so requires additional setup and doesn’t offer the same level of native support or flexibility.
Scalability
K2View’s architecture allows for high throughput by processing data in parallel across multiple micro-databases. It scales easily across environments and can handle large datasets with minimal slowdown.
Oracle is optimized for scale within Oracle environments, but performance may decline when working with very large databases. Masking jobs run on the same engine as the database, which can lead to slower execution unless resources are carefully managed.
Ease of Deployment, Administration, and Maintenance
K2View’s cloud version offers a relatively quick start, but on-prem deployments can be more involved due to initial data modeling and architecture setup. Once configured, the system is highly automated and adaptable.
Oracle’s masking tools integrate directly into existing Oracle infrastructure but come with a steep learning curve. Enterprise Manager and Application Data Modeling are powerful but not always intuitive, and updates to schemas often require manual adjustments to masking definitions.
Real-Time Capabilities
K2View supports dynamic, on-the-fly masking, allowing data to be anonymized as it moves through systems. This is useful in environments that need real-time protection.
Oracle’s solution is focused on static masking for test or dev environments. Real-time masking (data redaction) is offered only through a separate Oracle product and is not part of the Data Masking and Subsetting Pack.
Why PFLB Data Masking Tool Is a Better Choice Than Oracle Data Masking or K2View
PFLB’s Data Masking Tool was built to address the core challenges that make tools like Oracle and K2View complex or restrictive. It offers high-speed, database-level anonymization with a lightweight footprint, making it easier to deploy, scale, and integrate across environments. This is another answer to the Orcale vs K2View question.
Key Features
- Direct database-level masking for Oracle, PostgreSQL, and SQL Server
- Performance benchmarked at over 1 million rows per minute
- Supports bulk and incremental masking without affecting live systems
- Simple, code-based configuration — no complex modeling or GUI setup
- Compatible with CI/CD workflows and automated testing pipelines
- Deployment flexibility across on-prem, cloud, and containerized environments
- SOC 2–certified, with full support for GDPR, HIPAA, CCPA, and PCI DSS
Why It’s the Better Choice
Unlike Oracle, PFLB isn’t tied to a single database ecosystem. And unlike K2View, it doesn’t require complex architecture, data modeling, or heavy onboarding. The tool is designed to be operated by engineering teams without the need for deep platform training or specialized support.
In terms of performance, PFLB outpaces Oracle’s in-database masking and offers more consistent speed than K2View’s micro-database-based operations. It can be easily embedded into automation pipelines, making it a natural fit for fast-moving DevOps environments.
It’s also more accessible from a cost and licensing perspective. There’s no vendor lock-in, no need to license an entire enterprise database platform, and no overhead for features you won’t use. You get a focused tool that does one thing exceptionally well: fast, reliable, and secure masking for sensitive data.
Final Thought
Looking at K2View vs Oracle comparison, every organization approaches data masking with different constraints — some prioritize integration within a specific tech stack, others need broad system coverage or advanced automation. Oracle works well for those deeply embedded in its ecosystem. K2View offers flexibility and scale, especially for complex, multi-source environments.
But for teams looking to start fast, move efficiently, and avoid overhead, PFLB’s Data Masking Tool stands out. It doesn’t require long setup cycles, niche expertise, or enterprise licensing layers. It simply works — reliably and quickly.



