

Site Reliability Engineering (SRE) is a set of principles and practices that applies software engineering techniques to IT operations. The primary goal of SRE is to build and maintain scalable, reliable systems by automating manual processes, managing system health, and balancing the need for new features with the need for stability.

SRE breaks down traditional silos between development and operations teams, creating a unified approach to building and maintaining software systems. By embedding reliability into the design and development process, SRE ensures that systems are not only functional but also resilient under real-world conditions.

Key Takeaways
- SRE combines software engineering and operations to ensure reliable, scalable systems.
- Core practices include SLIs, SLOs, and error budgets to balance reliability with innovation.
- SREs automate manual operations (“toil”) and embed observability into infrastructure.
- Critical for high-traffic systems where uptime and resilience are business priorities.
- PFLB highlights SRE as essential for performance-driven organizations.
Introduction to SRE
In today’s fast-paced digital environment, ensuring that your systems are reliable, scalable, and resilient is more critical than ever. This is where SRE comes into play. Originally pioneered by Google, SRE has grown into a crucial discipline that blends software engineering with IT operations to create highly reliable systems. By integrating SRE, the development team can work alongside operations to build and maintain robust systems, ensuring they meet the demands of modern software environments.
The Role of a Site Reliability Engineer

At the heart of Site Reliability Engineering are the professionals who bring it to life: Site Reliability Engineers (SREs). These engineers combine software development skills and expertise in IT operations, including systems administration, to ensure that systems are both scalable and reliable. Their work goes beyond traditional operations tasks by focusing on performance engineering definition, automation, performance optimization, and continuous monitoring. The site reliability engineer’s role is critical in bridging the gap between development and operations, using software engineering principles to solve infrastructure challenges. This approach allows them to maintain system stability while driving ongoing improvements and accommodating new features.
How Site Reliability Engineers Collaborate with IT Operations Teams
Site Reliability Engineers (SREs) work closely with operations teams to ensure that both development and operations are aligned toward the common goal of maintaining system stability. This collaboration involves integrating software development practices into IT operations to create a more seamless and efficient workflow. By working together, SREs and the development team, including DevOps teams, can address potential issues before they escalate, automate repetitive operations tasks, and ensure that systems are prepared to handle the demands of modern business environments. This close partnership allows organizations to maintain high levels of performance and endurance, even as they scale.

The Evolution of SRE
SRE was born at Google when they sought a new way to manage large-scale, complex systems that needed to be highly reliable. A traditional operations team couldn’t keep up with the demands of such fast-paced environments, so Google introduced SRE as a way to scale its infrastructure efficiently.
Today, SRE is widely adopted by organizations across various industries, from tech giants to financial services, healthcare, and beyond. The role of an SRE is now seen as essential in maintaining the health of mission-critical systems.

Core Principles of SRE
To understand what SRE is, it’s important to delve into its core principles:
Emphasizing Reliability as a Key Feature
Reliability isn’t an afterthought in SRE; it’s a fundamental design principle. SRE teams work to ensure that services meet defined reliability targets, known as Service Level Objectives (SLOs) while managing error budgets to balance new features with system stability. Many forward-thinking teams also explore the benefits of chaos engineering to proactively identify system vulnerabilities before they impact users. Central to this approach are service level indicators that measure crucial aspects like latency, throughput, and error rates.
Automation is Crucial
Manual operations are prone to error and inefficiency. SRE focuses on automating tasks like monitoring, alerting, and even system recovery to improve speed and accuracy while maintaining error budgets to ensure that reliability goals are met. Additionally, incorporating automation software testing can help streamline testing procedures, ensuring that software is thoroughly tested under various conditions, further enhancing system reliability.
Reducing Toil
Toil refers to repetitive, manual tasks that do not add enduring value to the system. SRE aims to minimize toil by automating these tasks, freeing engineers to focus on higher-value work.
Blameless Postmortems
When incidents occur, SRE teams conduct blameless postmortems to learn from failures without assigning blame. This approach encourages a culture of transparency and continuous improvement.
Balance Between Innovation and Reliability:
One of the key challenges in SRE is balancing the need to innovate with the need to maintain reliable applications. SRE practices ensure that new features are rolled out without compromising system stability.
How SRE Differs from Traditional IT Operations
While traditional IT operations focus primarily on maintaining systems and responding to incidents, SRE takes a more proactive approach:
Proactive vs. Reactive:
SRE emphasizes preventing incidents before they happen through monitoring, automation, and engineering best practices, whereas traditional IT often reacts to incidents as they arise.
Software Engineering Mindset:
SRE brings a software engineering mindset to operations, using code to manage infrastructure and automating repetitive tasks.
Measurable Reliability:
SRE relies on data-driven decision-making, using metrics like SLOs and SLAs (Service Level Agreements) to quantify and improve system endurance. For a deeper understanding of how these practices fit into broader operational strategies, explore what is release management, which delves into the processes and deployment strategies that ensure smooth and efficient software releases.

Key Responsibilities of an SRE Team
An SRE team’s primary responsibilities include:
Service Level Management:
Setting, monitoring, and enforcing SLOs and service level agreements (SLAs) to improve system reliability.
Incident Response:
Quickly addressing incidents to minimize downtime and restore service, often using automated tools.
Performance Optimization:
SRE teams focus on analyzing system performance to identify bottlenecks and inefficiencies. To optimize performance, a site reliability engineer often uses the best load testing tools to simulate real-world traffic and stress conditions.
Capacity Planning:
Ensuring that systems can scale efficiently to meet future demand, often using predictive modeling and performance data.
Infrastructure Automation:
Automating infrastructure management tasks like provisioning, scaling, and configuration management to improve efficiency and reduce the burden of manual operations tasks.
Tools and Technologies Commonly Used in SRE
SRE teams leverage a wide range of tools to achieve their goals, including:
Monitoring and Alerting:
Tools like Prometheus, Grafana, and Datadog are used to monitor service health and alert engineers to potential issues before they impact users.
Automation:
Configuration management tools like Ansible, Puppet, and Terraform help automate infrastructure management tasks.
Incident Management:
Platforms like PagerDuty and Opsgenie are used to manage incident response, ensuring that issues are resolved quickly and efficiently.
Version Control and CI/CD:
Tools like Git, Jenkins, and GitLab are essential for managing code changes and deploying new features.
Load Testing:
Although load testing is just one part of an SRE’s toolkit, it’s crucial for ensuring that systems can handle expected traffic loads. Tools like PFLB, JMeter and JMeter cloud load testing tool are commonly used for this purpose.
Key Metrics and KPIs for SRE Success
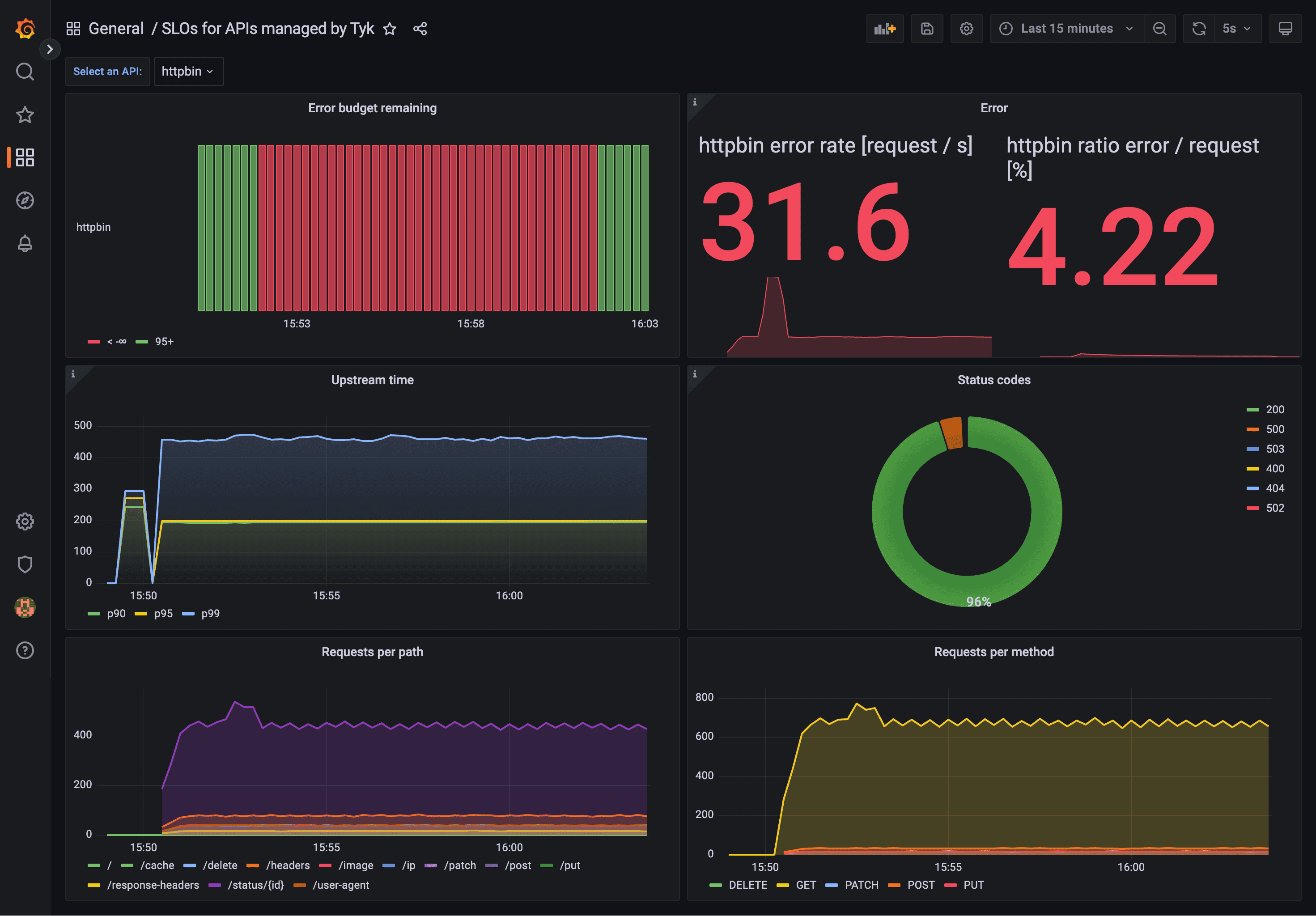
Measuring success in site reliability engineering involves tracking a range of key metrics and KPIs that shed light on system performance and scalability. Central to this are service level indicators (SLIs), which measure crucial aspects like latency, throughput, and error rates. These indicators help SRE team and the development team set and monitor service level objectives (SLOs)—the target levels for system reliability.
By keeping a close eye on these metrics, a site reliability engineer can ensure systems meet their reliability goals and swiftly pinpoint areas for improvement. Additionally, monitoring the number of incidents, mean time to recovery (MTTR), and the level of toil (manual, repetitive work) is vital for assessing the overall effectiveness of SRE approach. These metrics not only help maintain system stability but also clearly demonstrate the value of SRE to stakeholders.
The Importance of SRE in Modern Organizations
SRE is not just a technical discipline; it’s a cultural shift that transforms how organizations approach system reliability and operations. By adopting SRE and involving a site reliability engineer, companies can:
Improve System Uptime: Proactively manage stability to minimize downtime and ensure that critical systems are always available.
Enhance User Experience: Reliable software lead to better user experiences, reducing churn and increasing customer satisfaction.
Reduce Operational Costs: Automation and proactive management reduce the need for manual intervention, lowering operational costs.
Accelerate Innovation: With reliable IT-systems in place, teams can focus more on innovation, knowing that their infrastructure is solid.
Cultural Shift and Collaboration in SRE

The Counterintuitive Truth of Workplace Collaboration
One of the most significant impacts of adopting Site Reliability Engineering is the cultural shift it brings to an organization. SRE encourages a collaborative approach between development and operations teams, fostering a culture of shared responsibility for app reliability. This shift helps break down traditional silos, promoting a more integrated and holistic view of system management. By embedding SRE, organizations can create a culture where reliability is a shared goal, with everyone from developers to IT operators contributing to system stability and performance. This collaborative environment not only improves service reliability but also accelerates innovation by ensuring that all teams are aligned on common objectives.
How SRE Adapts Across Different Industries
While the core principles of what is SRE remain the same, their application can vary greatly across industries. In the financial services sector, for example, SRE practices often prioritize compliance and security due to the sensitive nature of financial data. Meanwhile, tech companies might focus on scalability and speed, leveraging SRE to enhance continuous integration and deployment (CI/CD) pipelines. In healthcare, SRE is crucial for maintaining system availability and protecting patient data, ensuring that critical systems remain operational at all times. By understanding the specific needs of each industry, SRE teams can customize their strategies to not only enhance system performance but also ensure alignment with industry-specific regulations and standards.
Building and Certifying an SRE Team
To effectively implement SRE, it’s crucial to have a team of Site Reliability Engineers with the right skills and expertise. Many organizations are investing in SRE training and certification programs to ensure their development teams are prepared to tackle the complexities of maintaining reliability. Certification programs offered by industry leaders like Google provide comprehensive training on SRE principles, tools, and best practices. These programs are meticulously designed to lay a solid foundation in SRE, encompassing everything from automation and monitoring to incident management and performance optimization. By prioritizing training and certification, organizations can cultivate a team of highly skilled site reliability engineers, capable of driving significant advancements in service reliability and performance.
Conclusion: The Future of SRE
As systems become more complex and user expectations continue to rise, the role of a site reliability engineer will only grow in importance. Understanding what SRE is and how it integrates with your organization’s operations and development teams is essential for building resilient, scalable systems.
Whether you’re just starting with SRE or looking to deepen your practices, embracing these principles can help you stay ahead in a competitive landscape. At PFLB, our load testing tool align with SRE needs, helping you ensure that your systems are ready for whatever comes their way.



