PFLB has recently started testing a large-scale banking system. It was extremely difficult to organize a well-established testing process, so we’re sharing our ideas for you not to reinvent the wheel.
Major Сhallenges when Testing Large Scale Systems
Software and information systems testing always involves a number of challenges. In this particular case, we were working for one of the biggest bank systems in the world, and the challenges were, as follows:
- the banking system was massive and had a large number of integrations with other systems of the bank;
- the system was supported and developed by a large number of people who were scattered in groups, organizationally and geographically;
- there were no specialists who had comprehensive information about the system;
- he system consisted of a large number of servers, implemented many protocols and integrations.
Purpose of the CCP Module
We focused on the customer’s cross-product profile (CCP) module of the business support and development platform (BSDP). The CCP module stores the bank’s customer products from various external subsystems. The task of the module is to speed up the load of the client profile for consumers of the service up to 0.5 seconds.
The CCP implements the concept of a customer-centric service, allowing you to instantly access information about the bank’s client and its products. More than 10 groups of functions were implemented in the CCP module, while performance testing was carried out only for the most frequent and resource-intensive ones. They were:
- loading data from external subsystems;
- data synchronization inside the module;
- forming the response in the consumer’s automated system;
- data migration – a one-time function that is launched at the start of the module and forms the client’s product card file.
Although it always starts with challenges, some of the features of the BSDP of the bank actually made it easier to design the testing process. For us, such advantages were:
Configuration of the Test Environment
The platform under consideration consisted of modules that implemented typical tasks of the bank. The BSDP modules were connected by intermodule transport (IMT). The BSDP was also connected to external systems by the module interface (MI) receiving messages from the enterprise service bus (ESB).
The BSDP was located in two transport architectures at that moment. A slow transition to the OpenShift architecture was started, while many solutions were still in the architecture of the last generation, implementing the MI+IMT bundle.
BSDP modules are hardware clusters of application servers and databases, interconnected by IMT. All modules had a typical hardware configuration, which allowed us to speed up and simplify development and testing.
he CCP module consisted of 16 servers with installed applications designed to process the incoming message flow efficiently. Additionally, one application server was utilized to create the primary client file, a process executed once during the module’s initialization. At this stage, the CCP database was populated with information about the client’s products, ensuring data security and privacy through integrated data masking software.
Three database servers were used – the main server and an active functional stand-in. Switching between the main and stand-in contours was performed through the application log of the BSDP.
Two architectural levels are being tested – the module level, where the performance of one module is determined, and the integration level, where the performance of a bunch of interacting subsystems of the BSDP is determined (in the target architecture, the CCP module + MI)
One dedicated server was used to stub requests from the CCP module to external systems at the IMT level. Test data was stored on separate servers in data pools.
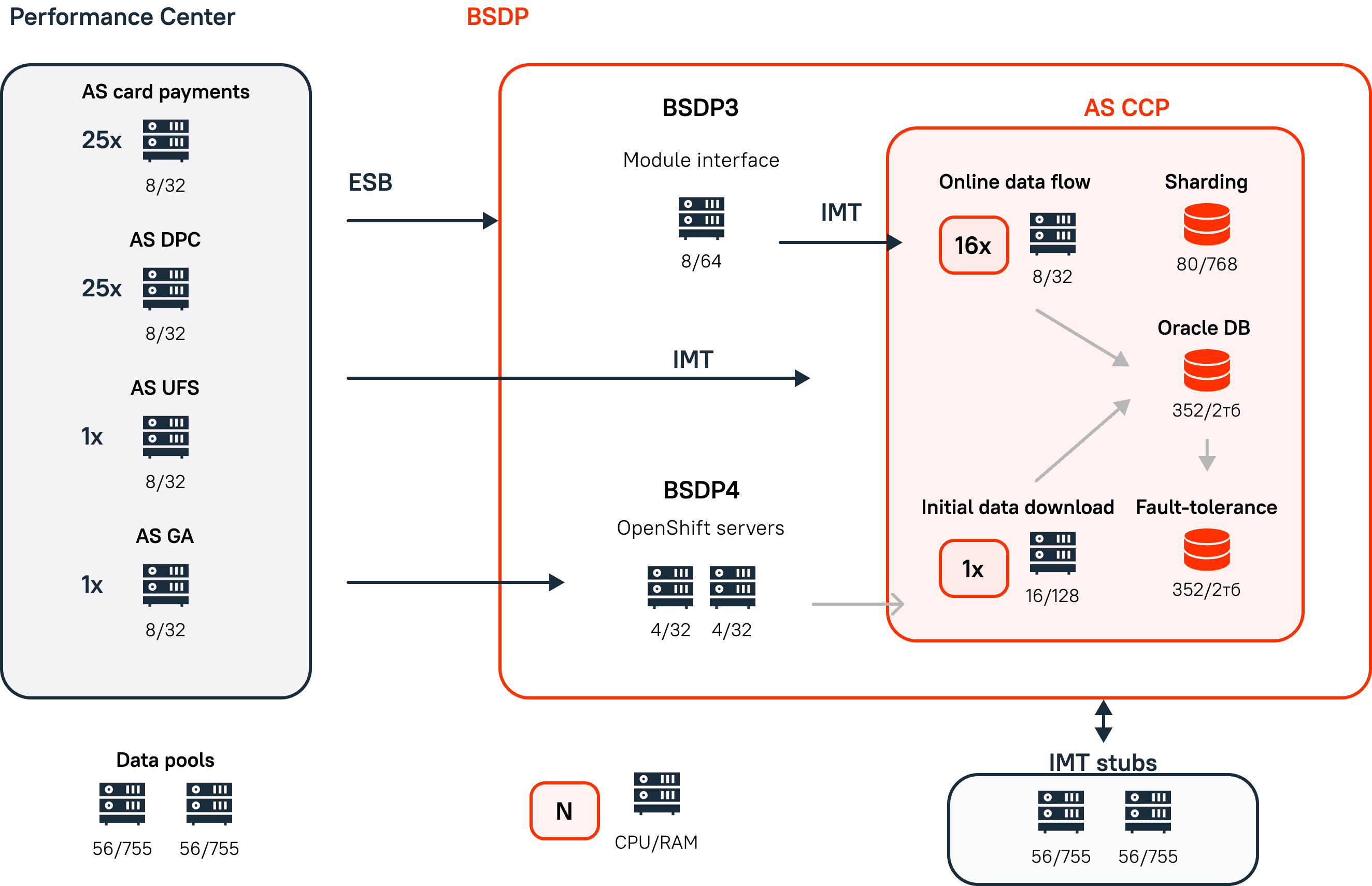
Figure 1. Configuration of the performance testing environment.
Tests Performed
The release cycle equaled two weeks. During this period, we conducted maximum search tests, stability tests, fault tolerance tests, and bottleneck tests.
Non-functional Requirements
The load profile was taken from the production for the peak season of the previous year. For three groups of CCP operations, the performance was set according to statistics collected from the production. For a data migration operation that runs once at the start of the module, performance evaluation was performed. The response time of the CCP module from the moment of the incoming request from the ESB and to the return response in the ESB was about 0.5 seconds. The standard load on the module was 15 thousand tps. In the maximum performance mode, where all functions were involved, about 20-30 thousand tps was fed to the module.
Four Operation Modes of the CCP Module in Performance Testing
1. Module start
Initially, there is no data about the client’s products in the module (Figure 2). A job is started for the initial data download, and they are copied from external systems in packages. As a result of the initial download, an up-to-date client data file is formed. In this case, the data is copied in batch mode and stored in the database.
2. Peak utilization of the module
A stream of messages is sent from external systems to the module. They are recorded as one message at a time. As a result, the client data file that was created at the start is updated.
3. The normal operation of the module
The database is finally formed. There is a data flow, but the client data file has already been formed, while some data is being clarified.
4. Data synchronization
The CCP module is a profile for the client’s products that are loaded from external systems. A mechanism has been implemented that checks CCP data for their compliance with sources. Synchronization works separately for each of the external subsystems (Figure 3). It runs at the moment of errors, during data creation, and it also runs in the background.
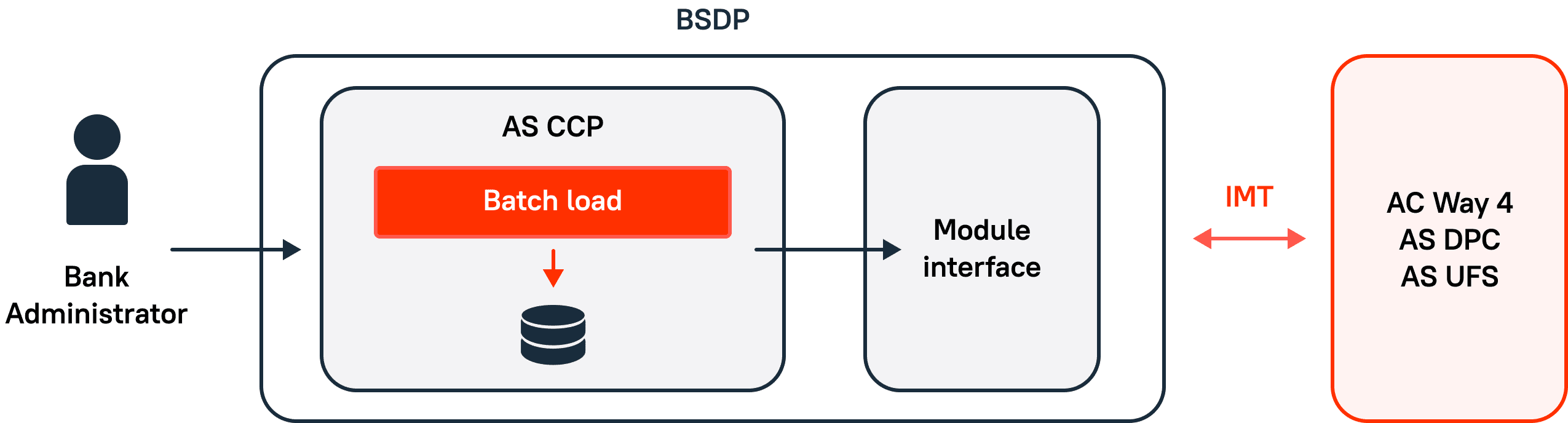
Figure 2. Initial data load into the CCP.
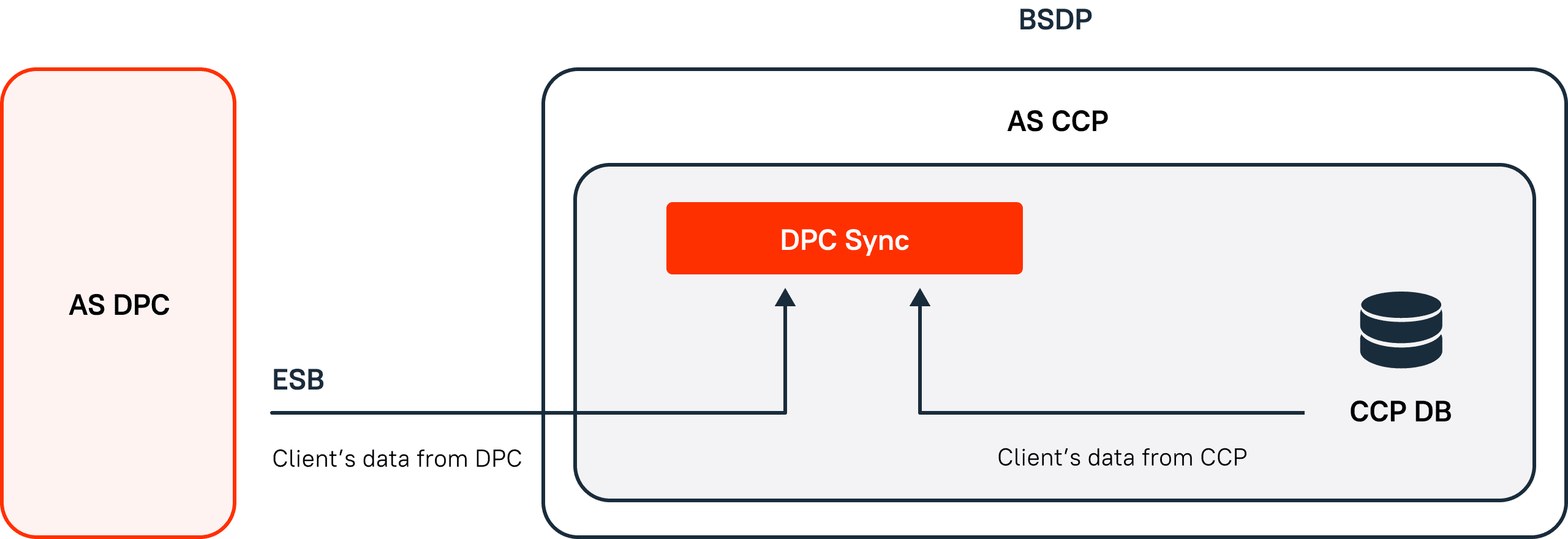
Figure 3. CCP data synchronization scheme.
Implemented Integration with External Systems in Performance Testing
At the moment, performance testing has implemented integration with 6 external systems: card payments in the bank, BSDP card payment service, data processing center (DPC), unified front-end system (UFS), government agencies (GA), and an app for online banking.
Architecture of Modular and Integrational Interaction
Let’s take a closer look at the transportation of a message from an external system to a CCP module
BSDP 3 Architecture
In BSDP 3, the external unified front-end system (UFS) sends a request through the ESB to the BSDP. At the entrance to the BSDP, the message is received by the module interface. Next, it transmits a message to the BSDP intermodule transport, where routing to the final module takes place. Once in the CCP module, the message is processed by the application servers and the result is recorded in the database.
Performance tests tested two levels of architectural interaction:
- Modular level. IMT queries were emulated in the CCP, which allowed us to find out the performance of one module.
- Integrational level. MI queries were emulated, and, as a result, the integration performance of MI + CCP was established.
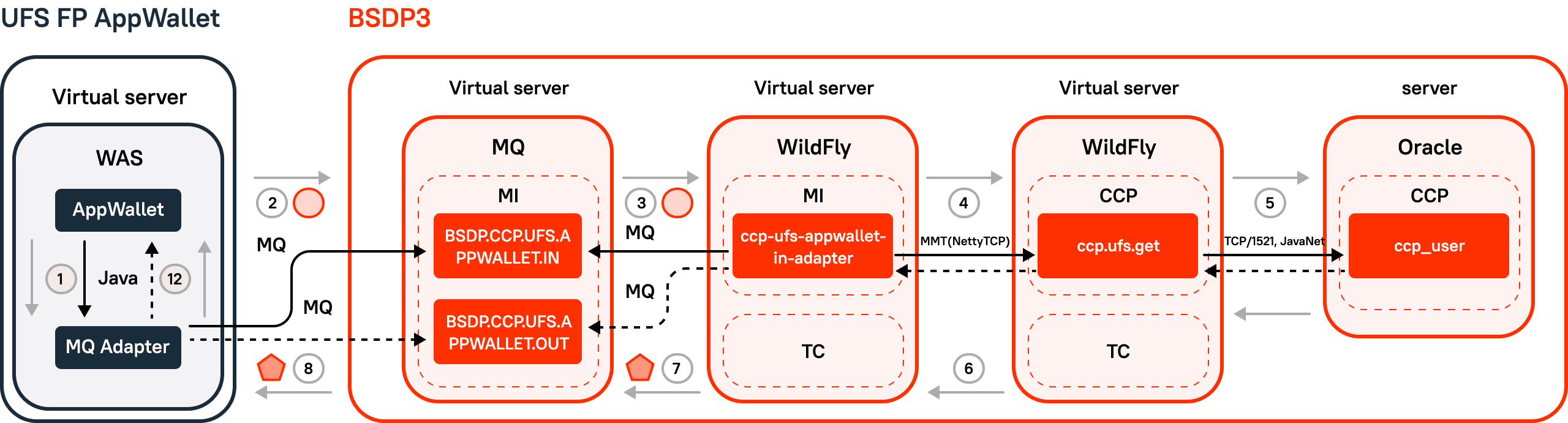
Figure 4. BSDP 3 architecture: IMT+MI.
BSDP 4 Architecture
The fourth generation of the transport architecture implements OpenShift technology. This approach uses servers on which OpenShift applications are deployed in the pods. Running applications in containers allowed us to scale the load. After exceeding the disposal limit, an additional pod with the application was launched. The incoming message stream is received by the Ingress server, sent by the Egress server, and routing is performed by the Proxy server. Two OpenShift arms are deployed in the performance testing environment and they handle the load simultaneously.
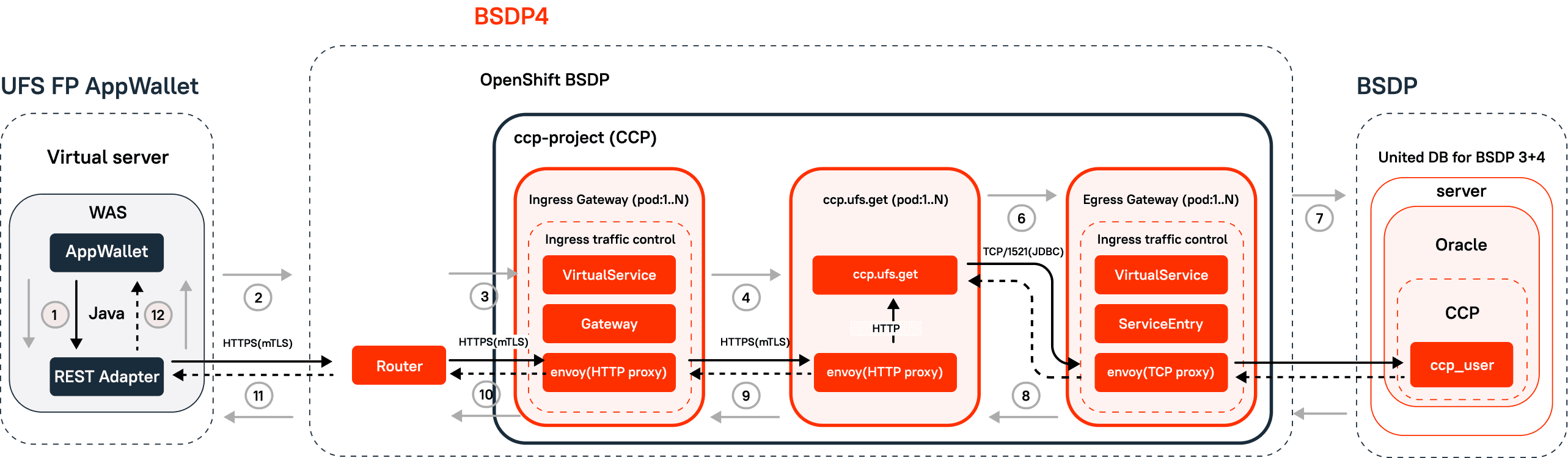
Figure 5. BSDP 4 architecture: OpenShift.
Monitoring
A separate development team implemented individual CCP monitoring for production. This monitoring was deployed in all test environments: system testing, development, integrational functional testing, elevator testing, performance testing, and SAT. On application servers, JMX metrics were aggregated by a special agent. Next, the metrics were written to kafka, after which they were subtracted to the Druid database and visualized by Grafana.
Implementing Data Pools
Separate Spring applications were launched on dedicated servers. These applications downloaded data from the CCP database at the start and formed data pools. Next, the scripts in the Performance Center addressed the applications and uploaded the prepared tables.
Data pools often become a bottleneck when the load is applied: their response time increases, and because of this, the applied load on the module decreases.
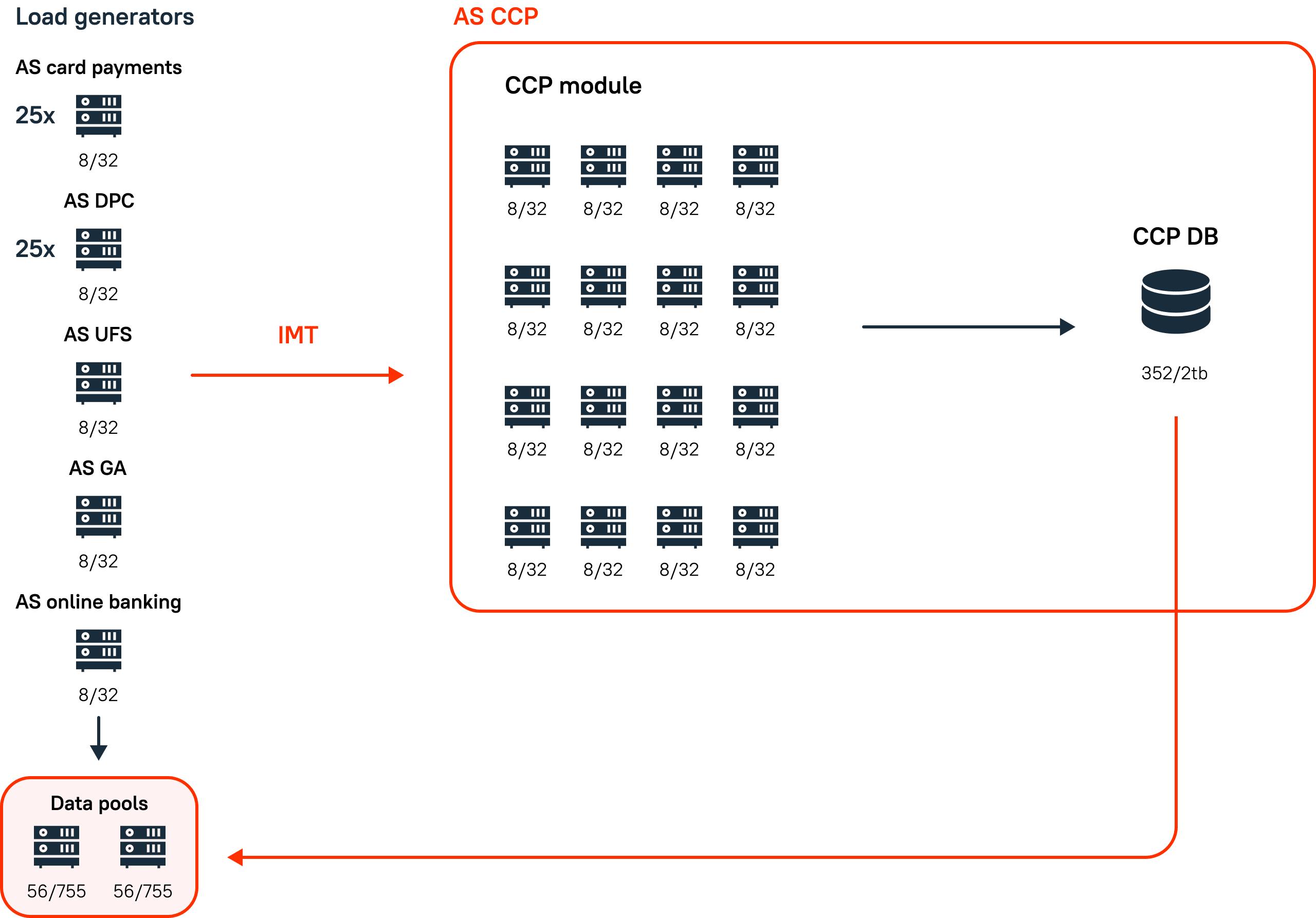
Figure 6. Data pool usage.
Conclusions
The massive bank system that we performance tested was architecturally complex, and it was this complexity that did not allow for the system to be tested completely. Our collaboration with the customer is still on (see also Core Banking System Test Automation): PFLB engineers carry out the tests in a release cycle of two weeks. In each release, a part of the large-scale system’s functionality is tested. In each cycle, we collect requirements for new functionality, implement performance testing scripts, conduct the tests, look for performance defects, and submit reports. The criteria for successful performance testing are the output of the subsystem to the production within the specified time frame, absence of performance defects, and a written release report.
If you are serious about a performance testing project for your huge software system, there is no better place than PFLB. You can always request a free demo: some of our 400+ engineers will be happy to share their experience of performance and load testing for massive banking systems and help you keep your end users happy. At least they have helped our 300+ enterprise clients we’ve had since 2008.



