No one disputes the fact that retail sales analysis is critically important to retail sales. It allows potential ways to increase sales volumes to be extracted from the ocean of current data. The faster this process occurs, the more successful the retailer will be in the market.
Our customer, a regular PFLB client and one of the largest retail chains, uses the SAP BW platform to perform this analysis. A few years ago, they decided to make it more efficient by selecting the fastest database management system (DBMS).
By then, PFLB had gained extensive skills in SAP load testing, so our client invited our company to join in this work.
We performed comparative load testing of the SAP BW platform against three database configurations:
We had to identify the system with the best performance so that the client could relate our research results to its financial capabilities and select the best technology for itself.
Since we were potentially spending several tens of millions of dollars, we felt the seriousness of the responsibility.
Project Features
Comparing high-tech software and hardware solutions, which include servers, data storage systems, communications equipment, and other know-how and specialized software, is not as simple as it seems at first glance.
An example
We planned to take the most frequently used reports, measure their execution time on three benches (a copy of the production server and two new solutions), and then compare the results.
However, database management systems have a rather large cache; some have a multi-tiered cache. After the first test run, the data is cached in memory. The second test run would only access the cache without changing the startup parameters.
Another example
Production systems are constantly under load. Performing tasks on an unloaded system or on a system that is not loaded in a consistent way will produce a distorted and obviously better result that cannot be compared with the production system.
It became clear that the testing must be more reproducible and that we would need to recreate a load identical to the load on the production server. As you can understand, the test benches could not work with real data, so the customer created its own method.
Step One: Create a Methodology
The customer’s methodology included several requirements for the project.
Requirement 1: The frequency of launching reports must be proportional to the frequency in the real system.
To satisfy this requirement, six months of report generation statistics were analyzed. The most time-intensive reports were selected. After all, any large organization does not have dozens but hundreds of reports, and their execution time depends on the launch conditions.
There’s a subtlety here: some reports are rarely launched but take hours to generate. Others are generated in a minute but launched thousands of times daily by different users. Therefore, the indicator of report generation intensity was the total time spent executing a report over six months, regardless of the launch parameters.
Requirement 2: The model must replicate the business day.
The customer’s typical business day was divided into two parts: users interacting with the system during the daytime and regular background tasks running at night. So, we created two profiles: a day profile and a night profile.
For clarity, I’ll show a real graph of the CPU load from one of the application servers. It shows the behavior during both daytime user activity and nighttime background tasks:
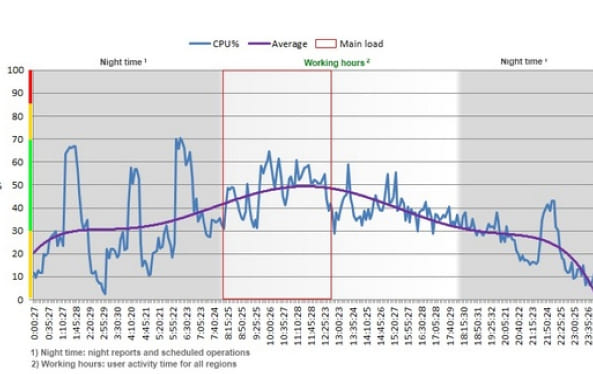
To make the picture as accurate as possible, in addition to the main profiles, a background load, or “noise,” was created since other operations occur on the server. This trick lets us imitate a similar load.
The daytime and background profiles were built based on statistics from the most loaded days of the month.
Step Two: Project Implementation
The project needed to achieve more than an understanding of how the system would behave. We also needed to test the scalability of the solutions being tested. For this, our team developed special load tests with increased user activity and profiles with data volumes increased by a factor of two, three, and five.
Moreover, it was important not only to compare quantitative indicators but also to assess qualitative characteristics. So, in addition to measuring the response time, we captured load profiles for the CPU, I/O, LAN, etc., from all infrastructure components and performed a qualitative analysis and interpretation of the data.
As a result
We obtained a large body of statistics, graphs, and information about database and hardware parameters.
Of course, several difficulties did arise during the implementation of the project.
Project Features
- Despite our accumulated experience in SAP testing, working with the Business Warehouse (BW) module was new for PFLB. Companies rarely decide to conduct load testing of their reporting system. They avoid updating it due to the high costs involved. In this regard, the client was an exception to the rule;
- The customer handled the hardware part of the project directly in collaboration with a vendor. PFLB was responsible only for the software part: preparing scripts, conducting load tests, and monitoring and analyzing the results;
- They were not able to provide us with hardware solutions with sufficient capacity, so the amount of data had to be reduced by 2.5 times. This added a week of additional work;
- The testing caused the motherboard to fail on one of the servers, which affected the time required to test the solution itself;
- Our client didn’t feel it was advisable to invest large sums of money in testing using LoadRunner, which is the tool usually used when working with SAP. We proposed an alternative: Apache JMeter. This approach required extra effort: for each report, we had to develop a special wrapper in the form of a web service, which was used to launch of reports and to which the load was applied. This solution had other drawbacks. But it was far less expensive and imposed restrictions that did not significantly affect the project results. So we used JMeter instead of LoadRunner;
Despite all the problems listed above, the pilot project slipped only one week, thanks to solid teamwork.
Step Three: Analysis of the Results
Our analysis gave the customer comparative assessments of performance indicators for Oracle DBMS, SAP HANA, and Oracle EXADATA
The project’s overall impact was a fourfold increase in performance and a reduction in data storage requirements due to compression and other technologies. In some cases, it accelerated user tasks 10–20 times, but in other cases, the processing speed decreased several times (not usually mentioned in marketing articles).
SAP HANA was recognized as the “fastest”
Although this option was the most expensive, the client followed our recommendation and purchased both SAP HANA and the hardware necessary to run it. Thus, PFLB has contributed to our customer’s subsequent growth as one of the most significant retailers.
Moreover, our joint project helped identify factors that limit the performance of the client’s SAP BW system. PFLB pointed out these problems and suggested ways to solve them.
In other words, such projects are not theoretical: they allow customers to choose a well-founded IT strategy for their business.



