Chaos engineering is a way to test how complex systems respond to unexpected problems. The idea is simple: introduce controlled failures and watch how the system behaves. This helps uncover weak points before they lead to costly outages. An approach that forces you to think about the unexpected, making it easier to build robust, fault-tolerant applications.
Done right, chaos engineering can make systems more resilient, reducing the risk of sudden breakdowns and improving overall performance. We also apply chaos engineering in our load testing services.

What is Chaos Engineering?
Chaos engineering is a discipline focused on testing how complex, distributed systems respond to unexpected failures. It involves intentionally introducing chaos engineering principles into production or staging environments to uncover weaknesses before they become costly outages.
The purpose of chaos engineering is to make systems more resilient by revealing how they behave under stress. Instead of waiting for failures to happen naturally, teams use controlled experiments to identify weak points and address them proactively. This approach forces teams to confront the messy, unpredictable nature of real-world traffic and usage, helping them design more robust, fault-tolerant architectures.
For example, you might simulate a server crash, introduce random latency, or cut off a critical service to see how your application responds. The goal is to learn from these controlled failures and build systems that can handle the unexpected.
New to performance testing? Learn more about concurrency testing.
Principles of Chaos Engineering
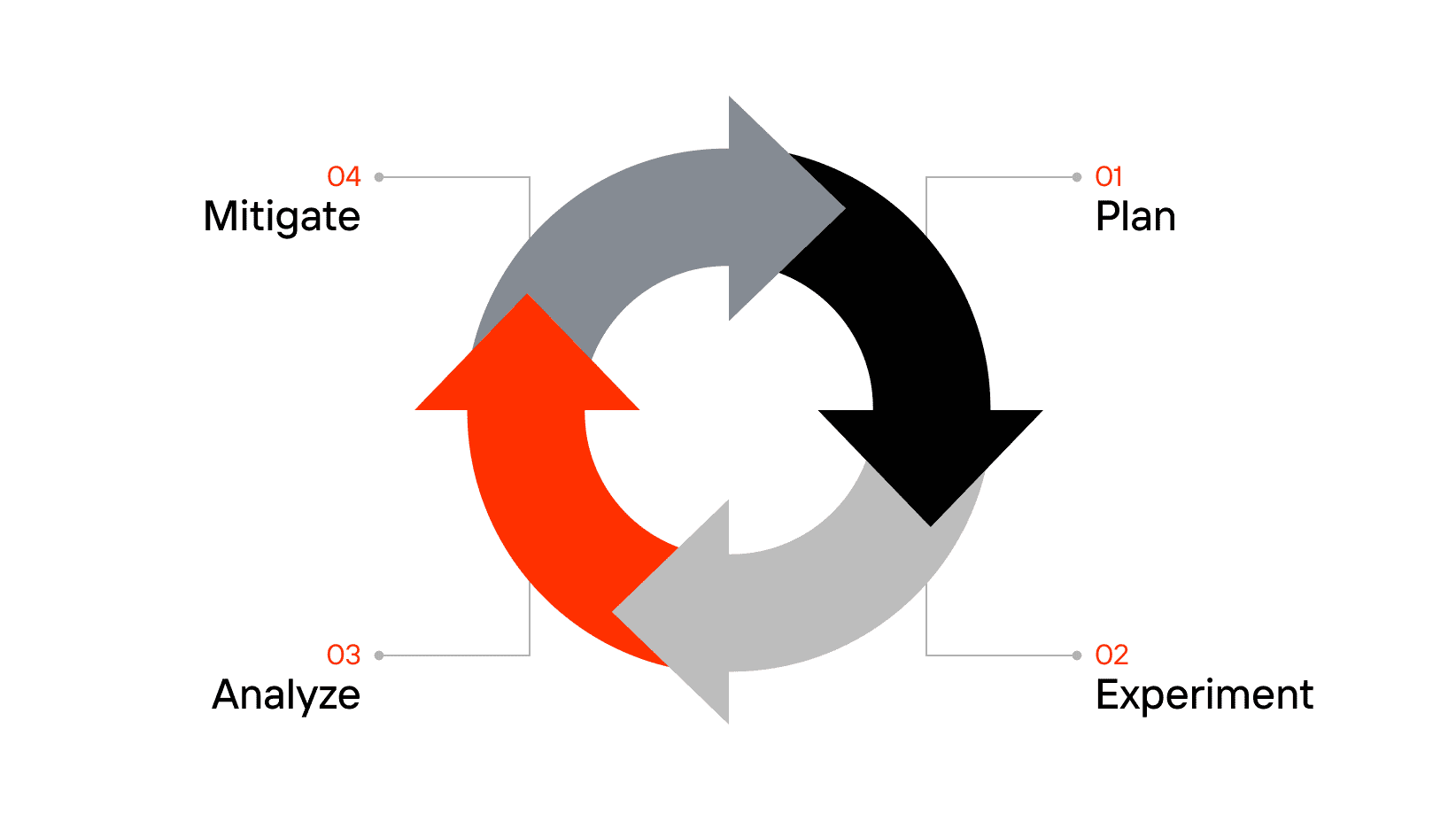
The principles of chaos engineering provide a structured approach to uncovering vulnerabilities in complex systems. They guide teams in designing experiments that reveal weak points without causing unnecessary disruptions. Here’s a breakdown:
- Plan
Before running any chaos experiments, it’s essential to have a clear plan. Define the steady state of your system — what “normal” performance looks like — and set a hypothesis about how the system should behave when things go wrong. This helps you measure the impact of your experiments accurately. - Experiment
Introduce controlled disruptions into your system, such as network latency, server failures, or unexpected traffic spikes. The goal is to simulate real-world chaos without causing permanent damage. For example, you might cut off a critical service or randomly kill server processes to see how the rest of the system responds. - Analyze
After each experiment, assess the results. Did the system behave as expected, or did it reveal unexpected weaknesses? This step is critical for understanding the impact of failures and identifying areas for improvement. - Mitigate
Use the insights gained from your experiments to strengthen the system. This might involve adding failover mechanisms, improving error handling, or redesigning parts of your architecture to be more resilient. The goal is to make future failures less impactful.
Benefits of Chaos Engineering
The value of chaos engineering goes beyond just finding bugs. It forces teams to confront the often messy, unpredictable nature of real-world systems. Here’s what that actually means:
- Uncovers Systemic Weaknesses
Traditional testing usually focuses on individual components in isolation, but real-world failures often come from unexpected interactions between those components. Chaos engineering reveals hidden dependencies and edge cases, helping teams address them before they become critical. - Improves Operational Readiness
Practicing failure means being ready for it. Teams that regularly run chaos experiments build a muscle for crisis management, reducing the panic and confusion when real outages occur. - Sharpens Scalability Planning
Chaos experiments highlight the cracks that only appear under extreme load, helping teams understand when and where their architectures start to break down. This makes capacity planning less of a guessing game.

- Drives Cultural Change
Chaos engineering shifts the focus from avoiding failure to understanding it. It is a mindset that encourages a more open, blameless culture where engineers feel comfortable experimenting and learning from their mistakes. - Guides Better Architectural Decisions
By revealing failure points early, chaos engineering influences design choices, leading to better architectures. It pushes teams to think about degradation and fault isolation from the start. - Reduces Long-Term Costs
Fewer outages and faster recoveries mean less firefighting, lower support costs, and a more stable user experience. It’s a long-term investment in system health that pays off as the system scales.
Chaos Engineering vs Traditional Testing
While both chaos engineering and traditional testing aim to improve system reliability, their approaches and goals are fundamentally different.
| Aspect | Traditional Testing | Chaos Engineering |
|---|---|---|
| Testing Scope | Focuses on specific components or isolated functions, like unit tests, integration tests, or UI validation. Typically aims to verify known behaviors. | Examines the entire system, including complex interactions between microservices, databases, and external dependencies. Looks for unexpected behaviors in real-world scenarios. |
| Failure Types | Catches known, repeatable bugs, like null pointer exceptions or incorrect API responses. | Introduces unpredictable failures, like random network latency, database timeouts, or node crashes, to expose weaknesses in system design. |
| Data Environment | Typically relies on controlled test data or synthetic inputs, which may not fully capture production complexity. | Uses live production data or realistic simulations to capture the unpredictable nature of real-world traffic. |
| Impact on Production | Usually run in test environments to avoid disrupting live services. Failures are isolated and controlled. | Often conducted in production or near-production environments, accepting the risk of real customer impact in exchange for realistic insights. |
| Automation and Tooling | Heavily relies on structured test scripts and automated pipelines (e.g., Selenium, JUnit). | Often uses specialized tools like Gremlin, Chaos Monkey, or Litmus, which are designed to inject controlled chaos into live systems. |
| Resilience Focus | Primarily about catching bugs and verifying expected behavior before deployment. | Focuses on building fault tolerance, validating failover mechanisms, and preparing for real-world chaos. |
| Mindset and Goals | Centered on validation and verification. Tests are considered complete when they pass. | Focused on discovery and learning. Failures are seen as valuable insights for improving system resilience. |
Types of Chaos Engineering Experiments
Chaos engineering experiments come in many forms, each targeting a different aspect of system reliability. Here are some of the most common types:
Latency Injection
Latency injection tests how a system handles delayed responses from critical services. This is particularly important in microservice architectures, where even minor delays can ripple through the system and create significant performance issues. For example, adding artificial delays to a key API can reveal bottleneck testing opportunities, where a single slow service impacts the overall user experience.
Fault Injection
Fault injection simulates the failure of individual components to see how the system responds. Killing server processes, dropping database connections, forcing timeout errors — it’s a way to test how well your failover mechanisms work and whether your error-handling logic can prevent a cascading failure.
Load Generation
Load generation involves simulating high traffic volumes to test the system’s scalability and capacity limits. It is similar to benchmark testing, where the goal is to find the system’s breaking point under extreme load. It’s a critical step for understanding how your architecture handles peak traffic.
Canary Testing
Canary testing involves gradually rolling out changes to a small subset of users before a full-scale release. Teams can catch issues early and roll back quickly if something goes wrong. It’s a less aggressive form of chaos engineering, but still valuable for identifying issues that only appear under real-world conditions.
Resource Starvation
Resource starvation tests push the limits of system resources, such as CPU, memory, or disk I/O. This can reveal how your application behaves when it’s competing for limited resources, potentially exposing deadlocks, memory leaks, or unoptimized code paths.
Network Partitioning
Network partitioning tests simulate network failures, like dropped packets or split-brain scenarios in distributed databases. Usually used with systems that rely on high availability and data consistency, as it reveals how well they handle communication breakdowns.
Best Practices for Chaos Engineering

Effective chaos practices and experiments go beyond basic break tests and require a deep understanding of your systems. Here’s a structured approach:
Understand Your System’s Normal State
Chaos experiments are only meaningful if you know what stability looks like. Establish clear performance baselines, including response times, error rates, and throughput. Without context, interpreting experiment results won’t lead you anywhere..
Set Clear Objectives for Each Experiment
Every chaos test should have a specific focus, and the goals need to be well-defined. Avoid unnecessary disruptions and ensure that experiments generate relevant insights.
Treat Failures as Learning Opportunities
Each failure is a valuable insight. And each unexpected behavior reveals a gap in system design or operational processes. Document the findings and adjust your architecture accordingly to prevent similar issues in the future.
Use Realistic Scenarios
Focus on real-world conditions. Instead of just pulling the plug on a server, simulate the subtle issues that are harder to catch, like intermittent network delays or slow database responses. This is the key chaos engineering approach that uncovers weaknesses that might otherwise go unnoticed.
Automate Chaos Experiments
Scaling chaos engineering requires automation. Manual testing can provide insights early on, but automated chaos experiments are more consistent and less prone to human error. Specialized chaos engineering tools can help standardize this process.
Make Continuous Improvement a Habit
Chaos engineering isn’t a one-time effort. The insights you gain should feed back into your development and operations processes. Regularly revisit past experiments, expand the scope of your tests, and set increasingly higher resilience goals.
Final Thoughts
Chaos engineering is a powerful way to find and fix the weak points in complex systems, but it’s just one piece of the puzzle. It’s great for uncovering hidden risks, but it doesn’t replace the basics — like proper unit testing, integration testing, and load testing.
If you’re serious about building reliable software, chaos engineering is a good start, but there’s a lot more to the story. The real work begins when you combine it with everything else you’re doing to keep your systems stable.