Some failures are evasive for unit tests or straightforward debugging. That’s when chaos engineering becomes essential — the deliberate injection of failure shows how your system behaves under real-world stress. In this article, we’ll walk you through the steps of chaos engineering. You’ll learn how to run experiments and get ready-to-use manifests for common issues — from inconsistent configurations to connection leaks.
Whether you’re new to chaos engineering or just looking for ideas to level up existing experiments, this guide is for you.
Why Chaos Engineering Matters
Your system may seem perfect, yet incidents still happen: services crash, systems degrade, outages occur, including security-related ones. Some of them are hard to reproduce and take a long time to investigate.
For example
Let’s focus on non-functional issues, such as network partitioning and infrastructure degradation. In these cases, any interaction point between services can become a point of failure.
These types of problems are hard to cover with standard unit or integration tests, as they often surface only under high load or in complex service chains. But those failures can be effectively simulated with chaos engineering. This practice helps you understand how the system as a whole — not just individual components — responds and prepares your team to act during real incidents (outages, degradations, or partial failures).
Fault Tolerance Testing or Chaos Engineering?
These two are often confused, yet serve different purposes. Fault tolerance testing is a subset of the broader chaos engineering practice.
| Fault Tolerance Testing | Chaos Engineering | |
|---|---|---|
| Goal | Verify how the system behaves under predictable and known failures (e.g., service crash, network outage) | Explore how the system responds to unpredictable, rare, or compound failures and uncover hidden weaknesses |
| Nature | Typically manual or automated tests, planned in advance | Structured experiments that introduce uncertainty and simulate chaos |
| Scope | Usually targets a single component or service | Involves the whole system and interactions between components |
| Tools | Failover setups, redundancy, failure simulation scripts, cloud-based fault injection tools | Chaos Mesh, Gremlin, Litmus |
The main idea of chaos engineering lies in conducting deliberate experiments to uncover systemic weaknesses. These experiments typically involve multiple teams and stakeholders and are designed to simulate real-world failure conditions in a controlled way.
Core Principles of Chaos Engineering
- Forming a Hypothesis About Steady-State Behavior
Start by defining your expectations: how should the system behave if something fails? Without this step, any experiment is meaningless — you won’t be able to tell if the result was normal or anomalous. - Simulating Real-World Events
We create failure scenarios that resemble real incidents — for example, network partitioning, database outages, or CPU saturation. The closer to reality, the more useful the insight will be. - Running the Experiments
Trigger the planned failures in a controlled environment and observe how the system responds — does it fail? Recover? What breaks, and why? - Automating Continuous Chaos Testing
To avoid relying on manual runs, chaos experiments should be integrated into your CI/CD pipeline. Regular execution keeps the system resilient and “on edge.” - Minimizing the Blast Radius
Experiments should be safe by design: if something goes wrong, it shouldn’t take down your entire production environment. Start small and gradually expand the scope.
The goal of chaos engineering isn’t to eliminate any possible incidents. It’s to make sure you’re prepared when they happen — and know exactly how to respond.
Chaos Mesh: A Powerful Tool for Experimenting
Chaos engineering is still a relatively young discipline — roughly 15 years old. Early tools were fairly basic and could randomly take down services or even entire clusters. Modern, second-generation frameworks support far more nuanced experiments — not only “killing” services, but combining with other conditions to simulate complex real-world failure modes.
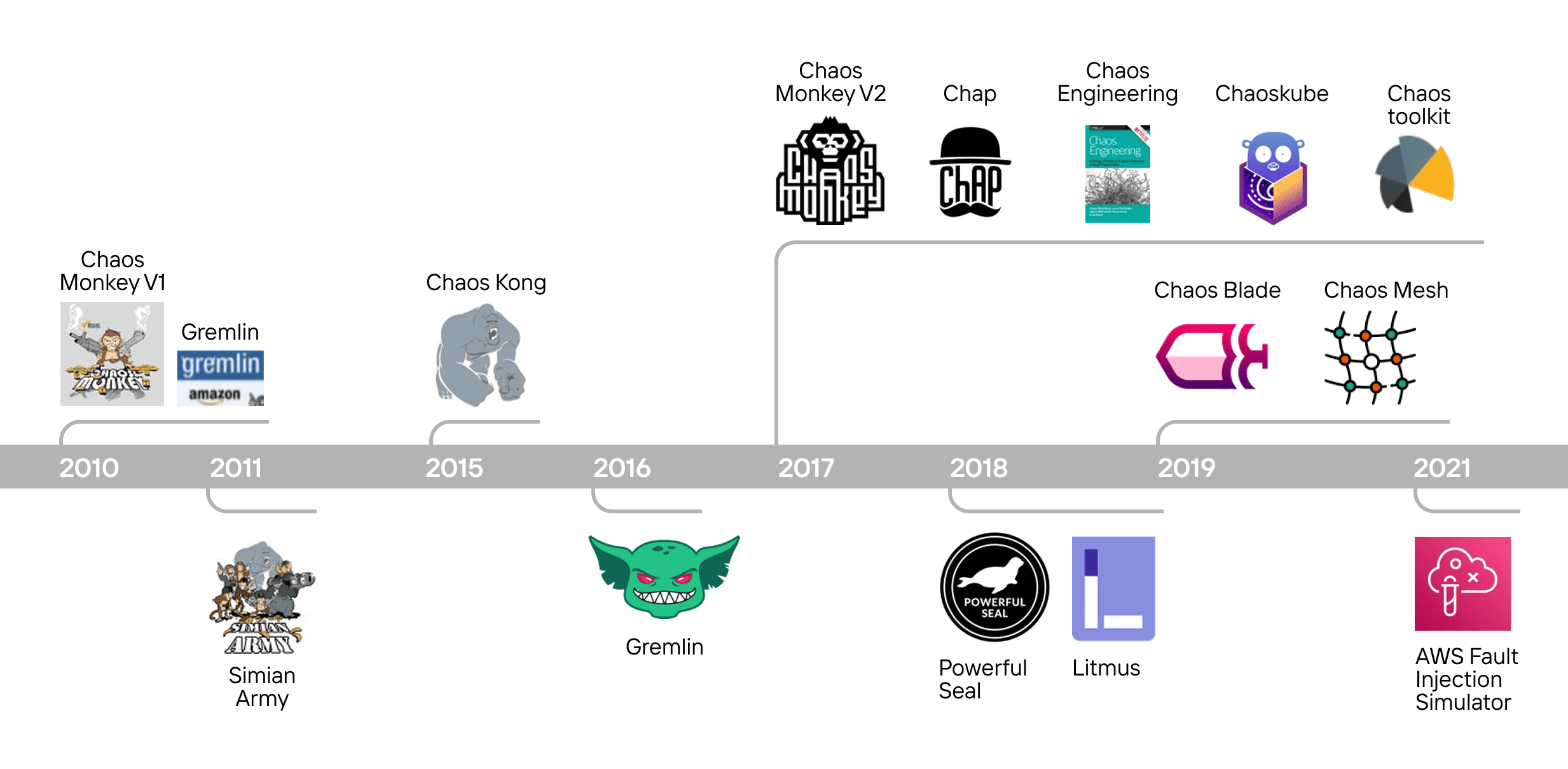
Over time, chaos experiments have become more intentional and precise. This led to the need for flexible, safe, and extensible solutions that could be embedded into real infrastructure without breaking it. That’s exactly the context in which Chaos Mesh emerged in 2019 — an open-source platform created by PingCAP, originally designed to test their distributed database, TiDB.
Chaos Mesh enables controlled fault injection not just into services, but deeper into critical layers like the file system, network, process scheduler, HTTP layer, Kubernetes controllers, and more. All of this is done using CRDs and YAML — familiar tools for Kubernetes engineers. This ease of integration is one of the reasons Chaos Mesh quickly became one of the most widely adopted tools in the chaos engineering ecosystem.
Chaos Mesh Capabilities
1. Perfect for Kubernetes — and Beyond
Chaos Mesh was designed as a native Kubernetes solution. It integrates seamlessly into clusters using standard Kubernetes mechanisms — Custom Resource Definitions (CRDs), controllers, admission webhooks — making it especially convenient for DevOps and SRE teams already operating in cloud environments.
Yet Chaos Mesh isn’t limited to Kubernetes. It also supports bare-metal nodes and virtual machines, enabling fault injection in heterogeneous infrastructures. This is crucial in real-world scenarios, where many companies run hybrid architectures — part of the workload might be stored in Kubernetes, while other parts run on dedicated hardware or legacy systems.
2. Wide Range of Built-in Experiments
Chaos Mesh comes with a rich set of pre-defined failure scenarios, each packaged as a separate CRD. That means every failure type — whether it’s an HTTP delay, a file system read error, or a pod restart — is defined as a native Kubernetes resource.
This eliminates the need to write custom scripts or manually assemble experiments. You simply describe the desired behavior in YAML and apply it like any other Kubernetes resource.
3. Composite Scenarios and Workflow Support
Chaos Mesh goes beyond isolated failure injection by allowing the creation of complex, multi-step experiments. These can be structured as chains or trees of actions, with fine-grained control over timing, parallelism, and dependencies.
For example
You can start by simulating network degradation between two services, then inject a file system write error, and finally kill a specific pod — all as part of a single pipeline orchestrated via the Schedule or Workflow resources.
This enables you to simulate a full-blown incident timeline, closely mimicking what might happen in real production outages. Such flexibility makes Chaos Mesh a powerful tool for systems where it’s important not only to survive the first failure, but also to withstand cascading effects that follow.
How Chaos Mesh Works and Where to Begin

Chaos Mesh full architecture overview.
Chaos Mesh is composed of two main components:
1. Chaos Dashboard
Web-based interface to create and run experiments through an intuitive UI. Each experiment is represented by a Kubernetes-native manifest, which allows you to interact with the system either via client libraries in various programming languages or directly through the Kubernetes API.
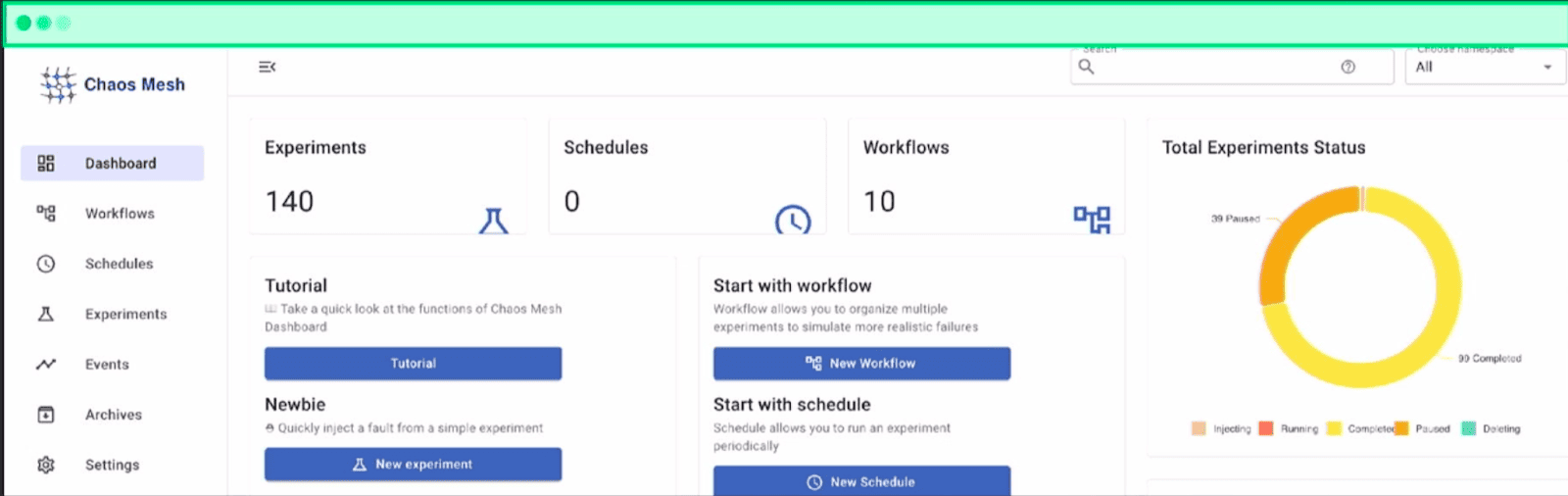
Chaos Dashboard home screen, showing experiment statistics, workflows, and other web features provided by Chaos Mesh.
2. Chaos Operator
Includes several key components:
- Chaos Controller Manager handles the orchestration and routing of failure injections between internal components, such as Chaos Daemon and chaosd.
- Chaos Daemon is deployed inside the Kubernetes cluster and is responsible for injecting failures into different runtime layers (e.g., Docker, containerd, CRI, etc.), based on instructions from the controller.
- chaosd, a standalone agent, can be deployed outside the cluster to inject failures into physical nodes (bare-metal). Under the hood, it leverages well-known system utilities like
tc,ipset,stress-ng, and more.
Through the Chaos Dashboard, users can select the target runtime (Kubernetes or host-level) and specify the type of fault to inject, offering fine-grained control over the blast radius and experiment environment.
Running Experiments: Four Common Scenarios
Cascading Requests
Imagine: a user is interacting with a service that reliably communicates with a database. Traffic is routed through a load balancer. At a certain point, something unusual happens on the backend, so one of the service replicas crashes.
The load balancer continues distributing the same volume of traffic, but now across only two remaining replicas. As pressure builds, more and more errors start appearing.

Now, let’s hit F5 and take a closer look at what’s happening. Open DevTools, simulate additional load — possibly background requests — that the system is now struggling to handle because earlier requests have already exceeded their timeouts. Suddenly, everything fails at once.
It’s a nasty failure mode — especially if it happens in production. Fortunately, we can simulate and analyze this scenario using a built-in experiment from Chaos Mesh.
PodChaos Experiment Example
kind: PodChaos
apiVersion: chaos-mesh.org/v1alpha1
metadata:
namespace: service-a
name: service-a-single-pod-failure
spec:
selector:
namespaces:
- service-a
labelSelectors:
app: service-a
pods:
service-a:
- service-a-ar12b
mode: all
action: pod-failure
duration: 20mselectordefines the scope — in this case, the specific service to be targeted.action: pod-failuremeans we’ll intentionally terminate one of the replicas.- If you want to randomly target any replica (instead of a specific pod), you can omit the pod name and use
mode: one. durationsets how long the experiment will run. Here, we’re simulating pod failure for 20 minutes.
What You Can Learn From This Experiment
- Monitoring anomalies under partial service degradation.
- Bugs triggered by service instability or interactions with neighboring components.
- Faults in deployment redundancy, especially when dev/staging doesn’t match production.
- Data for future hardening, expanded regression coverage, and insights to reduce tech debt.
Upstream Service Unavailability
Let’s say your service has evolved. Its functionality was expanded by adding new upstream services that provide additional data.

In this simplified example, there are two services with two replicas each — but in real-world systems, there could be dozens. Imagine a data aggregator system that pulls from various external sources, which can be added dynamically. This is a common architectural pattern.
Now, imagine Service B, an upstream dependency, becomes unavailable to Service A. On paper, this shouldn’t be catastrophic — after all, Service B is just one of many data sources, and it could be temporarily replaced with a stub or fallback without blocking the entire system.
But in real life, the unavailability of a single upstream service can sometimes lead to a full cascading system failure.
Let’s be clear: the system should be able to function for several minutes (or even hours) without that missing data. Instead, it locks up completely. To simulate and analyze this behavior, we can use a NetworkChaos experiment, which lets us manipulate the networking stack of the application.
⚠️ Important!
Your system should be in a stable state before running this test, especially if upstream services are external and beyond your control.
NetworkChaos Experiment Example
kind: NetworkChaos
apiVersion: chaos-mesh.org/v1alpha1
metadata:
namespace: service-a
name: service-a-to-service-b-net-part
spec:
selector:
namespaces:
- service-a
labelSelectors:
app: service-a
mode: all
action: partition
duration: 5m
direction: to
target:
selector:
namespaces:
- service-b
labelSelectors:
app: service-b
mode: allThis experiment partitions the network between Service A and Service B. The key elements here are:
-
action: partition— simulates a total network split. selector— the source of the disruption (Service A).target— the service being made unreachable (Service B).
Network partitioning is just one of several actions available through NetworkChaos. Others include packet delays, packet duplication, bandwidth throttling, packet loss or corruption.
What You Can Learn From This Experiment
- Single points of failure in a distributed architecture.
- Missing inter-service fallback logic or error handling.
- Opportunities to expand regression coverage with inter-service network tests.
- Data for improving service isolation and reliability.
File System Failures
This scenario is especially relevant if your service handles a lot of data.
Let’s slightly revise our previous example: instead of having services A and B communicate, we now introduce a storage layer. Imagine that your system is now part of a larger user-facing data pipeline.

For instance, your service might be responsible for aggregating data to generate a unified system dashboard. A user kicks off the pipeline in the evening, expecting results to be ready by morning. But something goes wrong, and the storage becomes unavailable. The next morning, support receives complaints, and your team spends hours debugging the root cause.
IOChaos Experiment Example
kind: IOChaos
apiVersion: chaos-mesh.org/v1alpha1
metadata:
namespace: service-b
name: io-fault-service-b
spec:
selector:
namespaces:
- service-b
labelSelectors:
app: service-b
mode: all
action: fault
errno: 5
path: /var/tmp/data/**/*
methods:
- READ
- WRITE
percent: 50
volumePath: /var/tmp/data/**/*
duration: 10merrno: 5simulates an I/O error (EIO) for read and write operations.pathandvolumePathpoint to/var/tmp/data/**/*— where your user data might be stored.methods: READ, WRITEapplies the error to both reads and writes.percent: 50introduces errors randomly with a 50% probability.duration: 10mlimits the experiment to 10 minutes.
When this experiment runs, you may see the same failure pattern as in a real user incident — delayed or failed pipelines, incomplete dashboards, and unhappy users.
For example, even a basic retry mechanism might be enough to prevent full pipeline failure. Alternatively, routing writes to a secondary storage location during an outage could provide resilience. There are many potential fixes — but the key is that chaos engineering reveals whether the service is prepared to handle these failure modes.
What You Can Learn From This Experiment
- How the service behaves under file system degradation.
- Which parts of the pipeline fail, and how those failures cascade.
- Whether retry logic is missing or insufficient.
- Whether a fallback storage solution could help mitigate the issue.
Contract Testing Through Fault Injection
Let’s say you have a core service (Service A) that communicates with an upstream service (Service B). Service A sends a request to the /hello endpoint on Service B. If it receives a 200 OK response, everything works as expected.
Now, imagine a failure occurs and Service B starts returning a 500 Internal Server Error instead. This is a fairly normal situation, but the team responsible for Service A didn’t anticipate or handle the error properly, leading to a cascading failure.
This is where HTTPChaos can help — a tool for injecting faults at the HTTP layer.
HTTPChaos Experiment Example
kind: HTTPChaos
apiVersion: chaos-mesh.org/v1alpha1
metadata:
namespace: service-b
name: replace-hello-response-code
spec:
selector:
namespaces:
- service-b
labelSelectors:
app: service-b
mode: all
target: Response
port: 80
path: hello
method: GET
code: 500
duration: 10mThis experiment uses HTTPChaos, a transparent proxy deployed inside the Kubernetes cluster that can intercept and modify HTTP traffic between services. It targets the /hello endpoint on Service B and forces it to return a 500 status code in response to all GET requests. The scope is limited using selector, targeting only Service B — but this can be narrowed further to specific pods or headers, even down to traffic from a single replica of Service A.
The selector field in HTTPChaos allows you to minimize the blast radius and test very specific scenarios — a critical capability when working in shared environments (e.g., staging or multi-tenant clusters).
You’re not limited to just modifying HTTP status codes. Chaos Mesh also supports:
- Changing response bodies.
- Introducing artificial delays.
- Manipulating headers, methods, and other aspects of the request/response cycle.
- Intercepting traffic conditionally, such as by request source or headers.
What You Can Learn From This Experiment
- Gain the ability to intercept and manipulate HTTP traffic between services
- Test the resilience of your service contracts — do clients behave correctly under failure?
- Explore the impact of fine-grained fault injection without taking down entire components.
- Identify contract violations or missing error-handling logic early in development.
Beyond the Basics: More Ways to Use Chaos Mesh
In this article, we’ve explored four common types of experiments using Chaos Mesh. But that’s just the beginning. Chaos engineering can take you much deeper into the behavior of your systems and the processes around them.
Chaos Mesh helps uncover not only technical faults, but also configuration-related issues. This is especially important if your environments (dev, staging, production) differ significantly — for example, fewer replicas on dev, no real traffic, or missing observability. These differences can lead to false positives, creating an illusion of stability.
Chaos engineering doesn’t just expose system-level issues — it also reveals organizational bottlenecks. Running meaningful experiments often requires collaboration across multiple teams: development, SRE, infrastructure, security. This process exposes real communication paths and helps evaluate how fast and effectively your organization responds when an incident occurs.
And at the company-wide level, chaos engineering can be used to run Disaster Recovery Plan (DRP) exercises — full-scale simulations of catastrophic outages.
Chaos Mesh is also well-suited for uncovering problems that don’t show up on standard metrics — like memory leaks, accumulating active or shadow sessions or resource buildup caused by internal service behavior, monitoring tools, or background jobs.
These are common in systems with high database connection churn, where each service maintains its own connection pool. Over time, connections accumulate and may lead to degradation or even full system failure.
Chaos Engineering Best Practices
To get the most value from chaos experiments, consider making them a routine part of your engineering culture:
- Run experiments regularly as part of your CI/CD pipeline.
- Include chaos tests in incident postmortems to avoid repeating mistakes.
- Integrate Chaos Mesh with monitoring and alerting to verify if your observability stack catches failures fast enough.
- Form hypotheses about system vulnerabilities and validate them through controlled experiments, not assumptions.
- Use chaos engineering as a training tool — nothing builds operational readiness faster than simulating real outages.