In any software development project, it is critical to carry out test plans that guarantee that the application’s performance requirements are met. From the most obvious perspective, performance tests are a set of tests that allow us to measure the speed of execution of a series of tasks in a system under certain conditions.
To achieve a good level of performance, the tests must begin at the beginning of the software development. Moreover, if we want the results to be as reliable as possible, our test environment should be as close as possible to that of production and never cross it with that of development or other tests.
Performance tests serve to:
- Demonstrate whether the system meets the established performance criteria;
- Compare systems to evaluate which one works faster;
- Validate and verify system quality attributes: scalability, reliability, use of resources;
- Measure which parts of the system or workload cause the assembly to perform poorly.
In this article, we will learn why a testing environment is important, explore the different types of software testing staging, and present recommendations for building a performance testing environment.
You can also read about load testing vs stress testing vs performance testing.
Why Is Test Environment in Software Testing Important
A test environment, also called a sandbox environment, is one of many factors that can help you optimize your new software. This is a parallel environment to a production environment, where you can test new applications, modules, migrations, and data import configurations and train users without compromising your organization’s actual data or disrupting operations. While this can increase the cost and schedule of implementation projects, in the long run, avoiding problems and unexpected situations can significantly save money and time.
As such, the test environment for any implementation plan should be part of the project. This is important for large businesses and new clients, especially if we’re talking about IT installations that partners are not yet familiar with or the implementation of a module that is not covered by basic finance, such as distribution or project management. Once the process is complete and the management solution is resolved, it is important to maintain the test environment, as it can be reused for any further testing or implementation.
Test environments can also be used to migrate solutions. This step is important in the development of the system and can have a major impact on execution if it is not executed or integrated properly. The test environment makes it possible to better identify any issues that may arise during migration and create solutions for migration to a production environment.
In essence
A test environment protects data and tasks during migration or implementation, prevents cost and delays, and highlights potential issues and ensures solutions are ready. Beyond performance validation, organizations must also consider understanding CSV validation requirements to ensure their systems meet regulatory standards and business expectations. This is an essential component of any business management system, ensuring that it works before implementing and modifying the production environment.
Staging or Pre-production Environment for Load Testing
When we are talking about staging for load testing, many questions arise.
We will discuss the theory and our practices in organizing such a staging.
In an ideal load testing framework, three things should fit the production environment: the load profile, the test data, and the staging. Most big organizations follow the rule that the test staging for load testing should be 100% identical to the production environment. Banks are complying with this rule for mission-critical systems. However, maintaining such a staging is costly. Therefore, staging often has fewer resources than production. When the staging has 60%+ of the resources compared to the production, the load testing results are also valid for the production. The test results can’t be applied to the production environment when the percentage is smaller.
It’s impossible to perform load testing on one architecture and then apply the results to another. For example, let’s say that your production system runs IBM POWER9, but the load tests were performed on Xeon: the test results don’t shed light on the production system load capabilities. To explore a variety of reliable and effective application performance testing tools that can support such efforts, don’t miss our detailed comparison of the latest options.
Even when you can’t create a staging with infrastructure and architecture as on production, there is still an opportunity to perform load testing and identify bugs and problems before the release. In this case, we use the comparison (also release) load testing to compare the maximal performance for two releases. We suppose that if the performance falls 10% in the tests, there will be the same change in production.
We’ll need to analyze many details and look at every test to discover the reason for the lowered performance and bottlenecks. If the bottleneck on staging has an analog on production, the error will probably be on production. For example, we have found a memory leak of 1 GB per day using a load test. On staging, the memory limit was 8 GB, so the test didn’t fail immediately. 32 GB was available on production, so the memory leak was not visible, but it could lead to problems after some time.
Sometimes, we apply comparison testing and tests to find the standard correspondence coefficient: how much fewer resources there are in staging compared to production.
Determining the Stand Correspondence Coefficient
Load tests are a subcategory of performance tests focused on determining or validating the performance of the characteristics of the application under test when it is subject to workload simulating the use it will have in production.
We determined the maximum system performance on a separate load profile for staging and production during the project. We use the results to calculate the stand correspondence coefficient that can be applied to make prognoses about the production performance.
The base formula to calculate the stand correspondence coefficient is listed below:
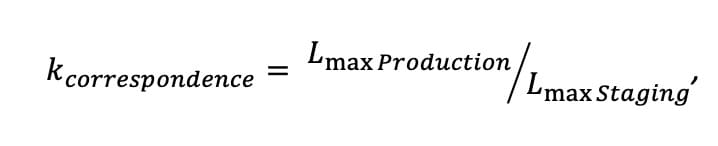
where Lmax Production is the maximal production performance and Lmax Staging – maximal staging performance.
Note
Each parameter stands for load level, matched to the 100% from the current production profile (taking into account operation restrictions).
While employing the comparison analysis, we take into account the following details:
- which hardware is used on staging and on production;
- which performance indicators are the closest tot the coefficient from the base formula;
- if the bottlenecks on staging and production are the same;
- if there are any additional bugs that can influence the testing accuracy.
A more precise stand correspondence coefficient can be developed in the performance test strategy after receiving detailed information about the client system and testing environment.
Production Environment Testing on Simplified Configurations
Often, it is not realistic to design a staging with all dependencies comparable to the production. Then, we are employing module testing, applying the load testing component-wise. So, we determine the most important system part and substitute the connected systems with the mock-ups.
We remove the systems that do not generate much load and substitute their load with a similar load from another component. Such changes on one hand allow us to simplify the staging configurations and to speed up testing, on the other hand there are certain simplification limits and some problems in the integration may be unnoticed.
Conclusion
Applications are becoming more and more complex with shorter development cycles, which require new and efficient testing and development methods. To manage this complexity effectively, including proper capacity planning in software testing is crucial. The performance of an application in terms of overall user experience is now the key factor in the quality of an application.
Therefore, a performance testing strategy must be implemented early in the project life cycle. First step: qualification of performance. It defines the test effort for the entire project.
A traditional approach to environment for qa testing would require the project to wait for the application to be assembled before starting to validate performance. In a modern project lifecycle, the only way to include performance validation at an early stage is to test individual components after each build and perform end-to-end performance testing after application assembly.
PFLB has served over 500 companies across all domains, from performance testing for financial systems and utility systems performance testing to Oil and Gas systems performance testing, and Technology. It is one of the pioneering software testing services in the industry. By trusting our expertise, your business can benefit from our software performance testing services.



